 new firmware: Jagon by Hardtoe
new firmware: Jagon by Hardtoe
Posted by hardtoe
|
new firmware: Jagon by Hardtoe November 08, 2011 02:15AM |
Registered: 12 years ago Posts: 74 |
Hello everyone!
I've started work on a new firmware. Current version is working, though experimental and unfinished. Do not install it on your printer unless you are brave. Check it out on github:
https://github.com/hardtoe/Jagon
It has a different software architecture than other firmwares. I want it to be easy to understand and easy to extend by other developers.
Here's a quick list of the main design decisions:
1) Protothreads - A lightweight threading library is used for all concurrent tasks. This makes it nice and easy to keep things flowing through the processing pipeline while not blocking any high priority functions. The protothread library is essentially a set of macros, so it uses minimal resources as well. I recommend checking out the website and the protothread.h file from the Jagon git repo.
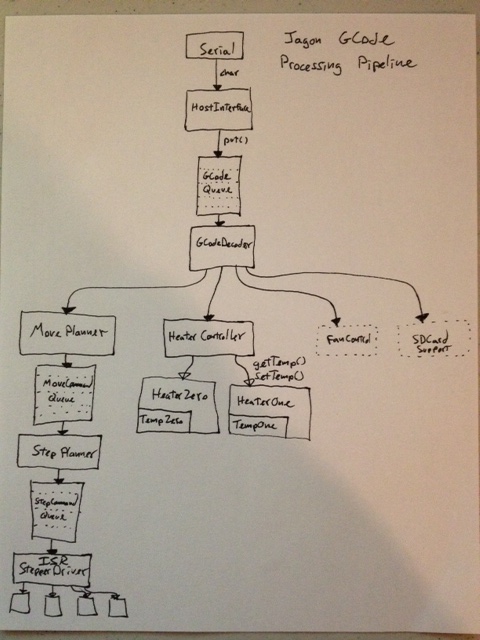
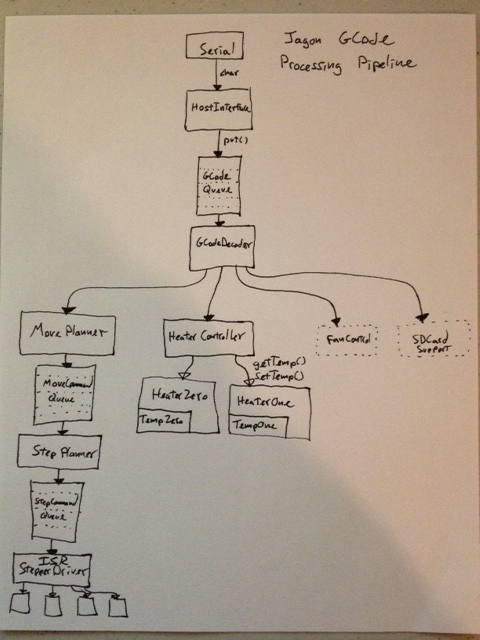
2) Split GCode processing pipeline - GCode processing is split into multiple pipeline stages. Each stage is its own C++ class. The stages communicate work items for the next stage using circular buffers. Each stage is also its own protothread.
3) Tiny interrupt used to drive the stepper motors - The stepper motor interrupt uses Timer1 along with the compare register to precisely time step pulses. The stepper interrupt only drives the stepper pins, it does not calculate which pins to step. Instead, the stepper interrupt pulls StepCommands from a queue and drives one step based on the next command in the queue. This means that serial communication will not be affected by the stepper interrupt. It also means that the StepPlanner can processes ahead of real-time to help hide any transient latencies in processing GCodes.
4) Try to keep it Open/Closed - Being the software nerd I am, I've been trying very hard to keep this firmware extensible without requiring a complete re-write to add any new feature. Part of the GCode processing pipeline is the GCodeDecoder class. Any GCodeHandler that processes GCodes registers with the GCodeDecoder. The GCodeDecoder then hands out GCodes from the gCodeCommandQueue based on which GCodeHandler can handle that GCode. Right now, there is the MovePlanner and HeaterController. If you want to add SD Card support, Fan Control support or GPIO support, they can be added as their own GCodeHandler and their tick() method can be added to the main loop(). In fact, that's exactly how those features will be added.
5) Assertions and unit tests. I have assertions right now that are only compiled in if DEBUG is defined. I don't yet have unit tests, but I will definitely be adding them using the google unit test framework. I love unit tests in my daytime job and they would be a fantastic development asset for this FW.
I think that's the big stuff. As for user features...well, that's slim pickings right now. I just did my first print with this FW a few hours ago. Currently:
a) It supports the same g-codes that Sprinter does:0, 1, 4, 28, 90, 91, 92, and it supports the heater related m-codes from Sprinter: 104, 140, 109, 105, 190
b) it doesn't yet support acceleration or inter-move planning
c) it won't burn your house down
Todo List:
-1) Use the feedrate given from the host rather than max (some little bugs here)
0) Speed improvements (it's not even using the Bresenham algorithm...it's currently using a much simpler algorithm)
1) Refactor the rest of the temperature code from Sprinter (currently only using thermistor code)
2) Inter-move acceleration planning like Marlin
3) Advance
4) SD Card support
5) Fan support
6) other?
Anyways, have fun taking a look at the code. It certainly is something different. I would love to hear some feedback from the community, especially from developers of the current generation of firmware!
I've started work on a new firmware. Current version is working, though experimental and unfinished. Do not install it on your printer unless you are brave. Check it out on github:
https://github.com/hardtoe/Jagon
It has a different software architecture than other firmwares. I want it to be easy to understand and easy to extend by other developers.
Here's a quick list of the main design decisions:
1) Protothreads - A lightweight threading library is used for all concurrent tasks. This makes it nice and easy to keep things flowing through the processing pipeline while not blocking any high priority functions. The protothread library is essentially a set of macros, so it uses minimal resources as well. I recommend checking out the website and the protothread.h file from the Jagon git repo.
2) Split GCode processing pipeline - GCode processing is split into multiple pipeline stages. Each stage is its own C++ class. The stages communicate work items for the next stage using circular buffers. Each stage is also its own protothread.
3) Tiny interrupt used to drive the stepper motors - The stepper motor interrupt uses Timer1 along with the compare register to precisely time step pulses. The stepper interrupt only drives the stepper pins, it does not calculate which pins to step. Instead, the stepper interrupt pulls StepCommands from a queue and drives one step based on the next command in the queue. This means that serial communication will not be affected by the stepper interrupt. It also means that the StepPlanner can processes ahead of real-time to help hide any transient latencies in processing GCodes.
4) Try to keep it Open/Closed - Being the software nerd I am, I've been trying very hard to keep this firmware extensible without requiring a complete re-write to add any new feature. Part of the GCode processing pipeline is the GCodeDecoder class. Any GCodeHandler that processes GCodes registers with the GCodeDecoder. The GCodeDecoder then hands out GCodes from the gCodeCommandQueue based on which GCodeHandler can handle that GCode. Right now, there is the MovePlanner and HeaterController. If you want to add SD Card support, Fan Control support or GPIO support, they can be added as their own GCodeHandler and their tick() method can be added to the main loop(). In fact, that's exactly how those features will be added.
5) Assertions and unit tests. I have assertions right now that are only compiled in if DEBUG is defined. I don't yet have unit tests, but I will definitely be adding them using the google unit test framework. I love unit tests in my daytime job and they would be a fantastic development asset for this FW.
I think that's the big stuff. As for user features...well, that's slim pickings right now. I just did my first print with this FW a few hours ago. Currently:
a) It supports the same g-codes that Sprinter does:0, 1, 4, 28, 90, 91, 92, and it supports the heater related m-codes from Sprinter: 104, 140, 109, 105, 190
b) it doesn't yet support acceleration or inter-move planning
c) it won't burn your house down
Todo List:
-1) Use the feedrate given from the host rather than max (some little bugs here)
0) Speed improvements (it's not even using the Bresenham algorithm...it's currently using a much simpler algorithm)
1) Refactor the rest of the temperature code from Sprinter (currently only using thermistor code)
2) Inter-move acceleration planning like Marlin
3) Advance
4) SD Card support
5) Fan support
6) other?
Anyways, have fun taking a look at the code. It certainly is something different. I would love to hear some feedback from the community, especially from developers of the current generation of firmware!
|
Re: new firmware: Jagon by Hardtoe November 08, 2011 02:29AM |
Registered: 12 years ago Posts: 74 |

|
Re: new firmware: Jagon by Hardtoe November 08, 2011 03:44AM |
Registered: 13 years ago Posts: 7,616 |
My honest opinion: "*sigh* yet another firmware". New firmwares spring to live more often than one can adjust them for one's own needs and as a result, well proven code dies.
Please don't take this personal, it's how the RepRap non-community works.
For example, Teacup does all this threading stuff already. It also has a multi-stage pipeline and independent G-code reading. And it's written in plain C, because C is more efficient and the ATmega's bottleneck is it's speed.
Please don't take this personal, it's how the RepRap non-community works.
For example, Teacup does all this threading stuff already. It also has a multi-stage pipeline and independent G-code reading. And it's written in plain C, because C is more efficient and the ATmega's bottleneck is it's speed.
| Generation 7 Electronics | Teacup Firmware | RepRap DIY |
|
Re: new firmware: Jagon by Hardtoe November 08, 2011 04:08AM |
Registered: 12 years ago Posts: 74 |
Hmm, I sure would be surprised if well proven firmware such as Marlin, Sprinter and Teacup died as a result of me writing this firmware in my own little corner of the world! I had no idea my actions could derail the reprap community! :p
EDIT: I think it's more like making a Mendel variant. There are so many variants, but i think it strengthens the community as it allows more designs to be vetted with developers and users. In the end, the community benefits because the best features from each project seem to end up combined in the next generation.
Edited 1 time(s). Last edit at 11/08/2011 01:00PM by hardtoe.
EDIT: I think it's more like making a Mendel variant. There are so many variants, but i think it strengthens the community as it allows more designs to be vetted with developers and users. In the end, the community benefits because the best features from each project seem to end up combined in the next generation.
Edited 1 time(s). Last edit at 11/08/2011 01:00PM by hardtoe.
|
Re: new firmware: Jagon by Hardtoe November 08, 2011 06:46PM |
Registered: 12 years ago Posts: 74 |
I'm planning on fixing the velocity calculations and enabling ramp acceleration until move planning is implemented.
The step calculation is the bottleneck of a RepRap firmware. Generally, the max speed of a firmware is limited by the worst case execution time of the step calculation. This makes it tough to support acceleration as a lot of calculation is required to compute a linear ramp.
However, Jagon FW can calculate many steps ahead of the current time. Therefore, the max feedrate is limited by the worst case execution time of X step calculations where X is the depth of the StepCommand queue. This is useful because we don't have to perform expensive calculations for every step. For example, we can use a form of the Bresenham algorithm to calculate the current velocity according to the given acceleration. For an acceleration of 25mm/s/s the velocity only changes 4000 times per second, this gives a period of 250us for step period calculation which requires a division operation. This means the heavy lifting of acceleration computation is amortized across many steps.
I think 50,000 steps per second is possible, though it seems that few machines would be able to ramp up to those speeds for mechanical reasons. It's a nice round number anyways.
I'll post more information, code and results as I implement acceleration. At that point, I think the firmware will be useful to me as much as Sprinter has been.
Also, I have pretty limited experience in 3d printing, so please correct me if any of my technical details are incorrect.
Edited 1 time(s). Last edit at 11/08/2011 06:47PM by hardtoe.
The step calculation is the bottleneck of a RepRap firmware. Generally, the max speed of a firmware is limited by the worst case execution time of the step calculation. This makes it tough to support acceleration as a lot of calculation is required to compute a linear ramp.
However, Jagon FW can calculate many steps ahead of the current time. Therefore, the max feedrate is limited by the worst case execution time of X step calculations where X is the depth of the StepCommand queue. This is useful because we don't have to perform expensive calculations for every step. For example, we can use a form of the Bresenham algorithm to calculate the current velocity according to the given acceleration. For an acceleration of 25mm/s/s the velocity only changes 4000 times per second, this gives a period of 250us for step period calculation which requires a division operation. This means the heavy lifting of acceleration computation is amortized across many steps.
I think 50,000 steps per second is possible, though it seems that few machines would be able to ramp up to those speeds for mechanical reasons. It's a nice round number anyways.
I'll post more information, code and results as I implement acceleration. At that point, I think the firmware will be useful to me as much as Sprinter has been.
Also, I have pretty limited experience in 3d printing, so please correct me if any of my technical details are incorrect.
Edited 1 time(s). Last edit at 11/08/2011 06:47PM by hardtoe.
|
Re: new firmware: Jagon by Hardtoe November 09, 2011 01:32PM |
Registered: 12 years ago Posts: 74 |
some notes from working on this last night:
25 mm/s/s is way slower acceleration than what i was using with Sprinter turns out my Sprinter config is setup for 1000 mm/s/s acceleration.
turns out my Sprinter config is setup for 1000 mm/s/s acceleration.
After implementing some naive acceleration algorithm, Jagon worked at 25 mm/s/s; of course it could not keep up at 1000 mm/s/s, just too many un-optimized divides. Also, I noticed that avr-gcc can output some fairly poor assembly if i'm not careful. I need to reorganize my stepper interrupt or re-write some of it in assembler if avr-gcc doesn't do what I want.
I still need a fast divide. This is to convert steps/second into the number of microseconds between steps. This division needs to be fastest when I have short step periods. The absolute shortest step period I imagine Jagon could support is set at the arbitrary size of 20us. If I'm naive, I can come up with an algorithm that computes that extremely fast, while still supporting other values:
Now i'm just dandy for the fastest case, but screwed if my step period needs to be 21us. Well, I can continue being naive for a little bit and see what happens:
This looks kindof stupid. But let's go through the numbers. Each comparison burns up some time, but for slow speeds, we gain an extra microsecond for each compare that we pass through. As long as we gain more time than we burn, we end up in the positive. AVR-GCC could implement each compare something like this:
And if AVR-GCC doesn't do this, it can be be-grudgingly written manually in inline assembly.
For each compare that fails, we execute 4 clocks worth of instructions. For the compare that matches, we execute 7 clocks worth of instructions. at 16MHz, the atmega can execute one cpu cycle every 62.5 ns. This means we consume 250 ns for each 1 us gained, plus an extra 188 ns to account for loading the result into a register and jumping past the rest of the compares.
That's pretty good, in fact, that's more than fast enough. However, it does use up program memory. I'm not yet sure how many values will need to be stored in the lookup table like this, but it could turn out to be an issue for devices with 32K. We'll see.
So the shortest periods are really fast now, but we still need a stop-gap between the shortest periods and longer ones. We can do this with even more efficient execution time by using a binary search tree. We have to do a linear search for the shortest periods because the binary search will always take a few compares and we can't afford that for those small periods. But for these medium length periods we have a little more elbow room to be efficient.
The final algorithm will look something like this (ignore the comparison values in the binary tree, they are wrong and I need to have some more caffeine before I calculate proper values):
For the actual division, I can probably get away with using the built-in unsigned 16/16 bit division algorithm. If that is insufficient, I will probably borrow one of Repetier's excellant optimized division algorithms and use that for medium-long periods, then i will fall back on the default division algorithm for more accuracy in the longer periods.
Additionally, there are some decisions to be made in terms of the size of the linear search in the beginning, the size of the binary search in the middle, when to use an optimized divide and when to use the regular arduino divide.
And finally, I need to see what sort of assembly AVR-GCC crafts for this algorithm and write a manual version if necessary.
I hope someone may find this useful, or find the flaws in it. I'm going to implement a real version tonight and see how it goes.
EDIT: fixed some bad grammar
Edited 2 time(s). Last edit at 11/09/2011 01:37PM by hardtoe.
25 mm/s/s is way slower acceleration than what i was using with Sprinter
turns out my Sprinter config is setup for 1000 mm/s/s acceleration.After implementing some naive acceleration algorithm, Jagon worked at 25 mm/s/s; of course it could not keep up at 1000 mm/s/s, just too many un-optimized divides. Also, I noticed that avr-gcc can output some fairly poor assembly if i'm not careful. I need to reorganize my stepper interrupt or re-write some of it in assembler if avr-gcc doesn't do what I want.
I still need a fast divide. This is to convert steps/second into the number of microseconds between steps. This division needs to be fastest when I have short step periods. The absolute shortest step period I imagine Jagon could support is set at the arbitrary size of 20us. If I'm naive, I can come up with an algorithm that computes that extremely fast, while still supporting other values:
// divide 1000000 by divisor
inline unsigned int fastDivide(unsigned int divisor) {
if (divisor >= 50000) {
return 20;
} else {
return 1000000 / divisor;
}
}
Now i'm just dandy for the fastest case, but screwed if my step period needs to be 21us. Well, I can continue being naive for a little bit and see what happens:
// divide 1000000 by divisor
inline unsigned int fastDivide(unsigned int divisor) {
if (divisor >= 50000) {
return 20;
} else if (divisor >= 47619) {
return 21;
} else if (divisor >= 45455) {
return 22;
} else if (divisor >= 43478) {
return 23;
} else if (divisor >= 41667) {
return 24;
} else if (divisor >= 40000) {
return 25;
} else {
return 1000000 / divisor;
}
}
This looks kindof stupid. But let's go through the numbers. Each comparison burns up some time, but for slow speeds, we gain an extra microsecond for each compare that we pass through. As long as we gain more time than we burn, we end up in the positive. AVR-GCC could implement each compare something like this:
subi // compare lower byte of divisor (1 clk) sbci // compare upper byte (1 clk) br // compare failed, jump to next if statement (2 clk) ldi // load lower byte of constant (1 clk) ldi // load upper byte of constant (1 clk) br // jump to end of subroutine (2 clk)
And if AVR-GCC doesn't do this, it can be be-grudgingly written manually in inline assembly.
For each compare that fails, we execute 4 clocks worth of instructions. For the compare that matches, we execute 7 clocks worth of instructions. at 16MHz, the atmega can execute one cpu cycle every 62.5 ns. This means we consume 250 ns for each 1 us gained, plus an extra 188 ns to account for loading the result into a register and jumping past the rest of the compares.
That's pretty good, in fact, that's more than fast enough. However, it does use up program memory. I'm not yet sure how many values will need to be stored in the lookup table like this, but it could turn out to be an issue for devices with 32K. We'll see.
So the shortest periods are really fast now, but we still need a stop-gap between the shortest periods and longer ones. We can do this with even more efficient execution time by using a binary search tree. We have to do a linear search for the shortest periods because the binary search will always take a few compares and we can't afford that for those small periods. But for these medium length periods we have a little more elbow room to be efficient.
The final algorithm will look something like this (ignore the comparison values in the binary tree, they are wrong and I need to have some more caffeine before I calculate proper values):
// divide 1000000 by divisor
inline unsigned int fastDivide(unsigned int divisor) {
if (divisor < 40000) {
if (divisor >= 50000) {
return 20;
} else if (divisor >= 47619) {
return 21;
} else if (divisor >= 45455) {
return 22;
} else if (divisor >= 43478) {
return 23;
} else if (divisor >= 41667) {
return 24;
} else {
return 25;
}
} else {
if (divisor > 30303) {
if (divisor > 33333) {
if (divisor > 35714) {
if (divisor > 38461) {
return 26;
} else {
return 27;
}
} else {
if (divisor > 34482) {
return 28;
} else {
return 29;
}
}
} else {
if (divisor > 35714) {
if (divisor > 38461) {
return 30;
} else {
return 31;
}
} else {
if (divisor > 34482) {
return 32;
} else {
return 33;
}
}
}
} else {
return 1000000 / divisor;
}
}
}
For the actual division, I can probably get away with using the built-in unsigned 16/16 bit division algorithm. If that is insufficient, I will probably borrow one of Repetier's excellant optimized division algorithms and use that for medium-long periods, then i will fall back on the default division algorithm for more accuracy in the longer periods.
Additionally, there are some decisions to be made in terms of the size of the linear search in the beginning, the size of the binary search in the middle, when to use an optimized divide and when to use the regular arduino divide.
And finally, I need to see what sort of assembly AVR-GCC crafts for this algorithm and write a manual version if necessary.
I hope someone may find this useful, or find the flaws in it. I'm going to implement a real version tonight and see how it goes.
EDIT: fixed some bad grammar
Edited 2 time(s). Last edit at 11/09/2011 01:37PM by hardtoe.
|
Re: new firmware: Jagon by Hardtoe November 09, 2011 03:46PM |
Registered: 12 years ago Posts: 74 |
another thought on the stepper interrupt and endstops.
the only time endstops should ever be triggered is when we are homing the machine. any other time it can be treated as a fatal error. if this assumption is correct, i can create an optimized stepper interrupt that never checks the endstops. then i may be able to create edge-triggered interrupts on the endstop pins that will report a fatal error to the host and halt the machine.
if the endstops aren't on interrupt-enabled pins, there may still be some optimization that can be done. i'll have to think about that.
the only time endstops should ever be triggered is when we are homing the machine. any other time it can be treated as a fatal error. if this assumption is correct, i can create an optimized stepper interrupt that never checks the endstops. then i may be able to create edge-triggered interrupts on the endstop pins that will report a fatal error to the host and halt the machine.
if the endstops aren't on interrupt-enabled pins, there may still be some optimization that can be done. i'll have to think about that.
|
Re: new firmware: Jagon by Hardtoe November 09, 2011 08:28PM |
Registered: 13 years ago Posts: 64 |
|
Re: new firmware: Jagon by Hardtoe November 09, 2011 08:56PM |
Registered: 12 years ago Posts: 74 |
|
Re: new firmware: Jagon by Hardtoe November 10, 2011 12:30AM |
Registered: 12 years ago Posts: 74 |
i was able to create a first pass of the fast division algorithm. i compared it against the avr-gcc integer division operation as well as the marlin's "calc_timer" method, which I believe performs the same function as the "fastDivide" function i wrote.
the results are promising:
I've got some more data on google docs that shows how the division time increases as the velocity decreases, it also has a pretty graph:
Division Time in Red Vs. Velocity
If you look at the graph you'll see a sharp rise in the execution time of the fast divide, this happens when it falls back to the regular avr-gcc division. I may want to delay that even further by adding another binary search tree. it would slow down the division for much slower speeds, but i don't think that would be an issue.
I've attached an Arduino sketch that contains the fast division algorithm as well as the testbench used to estimate the execution times if anyone is curious.
Edited 1 time(s). Last edit at 11/10/2011 12:38AM by hardtoe.
the results are promising:
for 12000 steps per second or more: Jagon fastDivide (us): 2.14 Marlin calc_timer (us): 3.18 avr-gcc unsigned int divide (us): 30.98
I've got some more data on google docs that shows how the division time increases as the velocity decreases, it also has a pretty graph:
Division Time in Red Vs. Velocity
If you look at the graph you'll see a sharp rise in the execution time of the fast divide, this happens when it falls back to the regular avr-gcc division. I may want to delay that even further by adding another binary search tree. it would slow down the division for much slower speeds, but i don't think that would be an issue.
I've attached an Arduino sketch that contains the fast division algorithm as well as the testbench used to estimate the execution times if anyone is curious.
Edited 1 time(s). Last edit at 11/10/2011 12:38AM by hardtoe.
|
Re: new firmware: Jagon by Hardtoe November 10, 2011 03:55AM |
Registered: 12 years ago Posts: 74 |
so i finally got rid of the silly line drawing algorithm i was using. i checked out the wikipedia page on the Bresenham algorithm and found a link to a 4D implementation. it was coded in basic, so i ported it over to C++ and slapped it into the StepPlanner. This made the StepPlanner code look like crud, but now my printer screams!
in fact, the firmware is able to step much faster than my printer can keep up, so the Z axis skips tons of steps and the Y axis skips every once and a while. i'll update git with the latest code. this has the 4D bresenham algorithm as well as the fast division algorithm.
in fact, the firmware is able to step much faster than my printer can keep up, so the Z axis skips tons of steps and the Y axis skips every once and a while. i'll update git with the latest code. this has the 4D bresenham algorithm as well as the fast division algorithm.
|
Re: new firmware: Jagon by Hardtoe November 10, 2011 11:03AM |
Registered: 12 years ago Posts: 74 |
after making some fixes i'm now able to run the FW on my printer with 1000mm/s/s acceleration up to 18181 steps per second, that's 227 mm/s on the Y-Axis.
the FW isn't missing any steps as far as I can tell. I print out a little message if the StepCommand queue underflows, haven't been seeing that. will be working on improving the speed even further.
the FW isn't missing any steps as far as I can tell. I print out a little message if the StepCommand queue underflows, haven't been seeing that. will be working on improving the speed even further.
|
Re: new firmware: Jagon by Hardtoe November 10, 2011 01:51PM |
Registered: 12 years ago Posts: 2,705 |
I have looked somewhat over your code. It looks nice and clean, but I'm not sure the programming style is fast enough in the end. Anyhow, here some infos, you may need.
If you do it right, you only need one division for step time calculation. The division from Marlin is very special and returns the timer value needed in their case. This probably is the wrong computation in your case. You can have a look at my solution
[github.com]
search for long CPUDivU2(unsigned int divisor)
It is a fast divide F_CPU/divisor. It uses a fast lookup table. If you need different divisions, you can change the lookup table easyly. It's not fully accurate but precise enough for timing computation and better then the 680 Steps/division gcc needs.
Acceleration to 18000 is not fast enough. Some peaple have extruder with 1300 Steps/mm and want it to run at 25 mm/s for fast retracts. That's 32500 Hz. I never thought of this, until they complained some errors due to this high frequency. Off couse, you can always clamp this to possible speeds. Still better then missing steps or nothing.
I don't know what you have planned for the final version, but some smaller avrs like sanguino only have 2,5kb RAM. So reduce your ram usage where ever possible. It may be needed later.
Repetier-Software - the home of Repetier-Host (Windows, Linux and Mac OS X) and Repetier-Firmware.
Repetier-Server - the solution to control your printer from everywhere.
Visit us on Facebook and Twitter!
If you do it right, you only need one division for step time calculation. The division from Marlin is very special and returns the timer value needed in their case. This probably is the wrong computation in your case. You can have a look at my solution
[github.com]
search for long CPUDivU2(unsigned int divisor)
It is a fast divide F_CPU/divisor. It uses a fast lookup table. If you need different divisions, you can change the lookup table easyly. It's not fully accurate but precise enough for timing computation and better then the 680 Steps/division gcc needs.
Acceleration to 18000 is not fast enough. Some peaple have extruder with 1300 Steps/mm and want it to run at 25 mm/s for fast retracts. That's 32500 Hz. I never thought of this, until they complained some errors due to this high frequency. Off couse, you can always clamp this to possible speeds. Still better then missing steps or nothing.
I don't know what you have planned for the final version, but some smaller avrs like sanguino only have 2,5kb RAM. So reduce your ram usage where ever possible. It may be needed later.
Repetier-Software - the home of Repetier-Host (Windows, Linux and Mac OS X) and Repetier-Firmware.
Repetier-Server - the solution to control your printer from everywhere.
Visit us on Facebook and Twitter!
|
Re: new firmware: Jagon by Hardtoe November 10, 2011 02:21PM |
Registered: 12 years ago Posts: 74 |
thanks for taking the time to look at the code Repetier! Right now the StepPlanner is doing just one division per step. I agree that 18k steps/second is not fast enough. I still have a lot of optimization left for the StepPlanner. I spent about an hour getting the bresenham algorithm working and that's when I was able to get 18k steps.
I can optimize that code by pulling several calculations out of the main step loop. I also want to further optimize the StepDriver, it's my stepper interrupt and it is about 150 instructions long...
Besides that, I'm considering ways to ditch the longs. I am considering making a uint24_t library that implements all the necessary operators. I believe that would allow for a decent speed up in the StepPlanner.
And finally, I can adjust the fastDivision algorithm to optimize for a more realistic step rate, rather than 50khz. For the highest step rate, this algorithm delivers an answer in about 1us. This would allow for step periods a few us shorter. And I'll check out your division routine as well!
I can optimize that code by pulling several calculations out of the main step loop. I also want to further optimize the StepDriver, it's my stepper interrupt and it is about 150 instructions long...
Besides that, I'm considering ways to ditch the longs. I am considering making a uint24_t library that implements all the necessary operators. I believe that would allow for a decent speed up in the StepPlanner.
And finally, I can adjust the fastDivision algorithm to optimize for a more realistic step rate, rather than 50khz. For the highest step rate, this algorithm delivers an answer in about 1us. This would allow for step periods a few us shorter. And I'll check out your division routine as well!
|
Re: new firmware: Jagon by Hardtoe November 10, 2011 10:53PM |
Registered: 12 years ago Posts: 74 |
so i went through and optimized my code a bit more. i got it down to a 50us period. then i started looking at the TimerOne.cpp code that i'm using. it looked fast. but then i looked...closer:
the first line has both a multiply and worse, a signed 32 bit divide. that blows my mind. removing that divide will give me a ton of headroom. it has to be eating up at _least_ 25 us every step. i guess i never wondered why this library let me specify periods in exact microseconds ok...time to fix this and see some super speeds 
EDIT: i'm retarded. it's a division between two constants. the 32 bit signed multiply is no good, so there is still an optimization available, just not at the scale as it would have been with divide.
Edited 2 time(s). Last edit at 11/10/2011 11:22PM by hardtoe.
void TimerOne::setPeriod(long microseconds) // AR modified for atomic access
{
long cycles = (F_CPU / 2000000) * microseconds; // the counter runs backwards after TOP, interrupt is at BOTTOM so divide microseconds by 2
if(cycles < RESOLUTION) clockSelectBits = _BV(CS10); // no prescale, full xtal
else if((cycles >>= 3) < RESOLUTION) clockSelectBits = _BV(CS11); // prescale by /8
else if((cycles >>= 3) < RESOLUTION) clockSelectBits = _BV(CS11) | _BV(CS10); // prescale by /64
else if((cycles >>= 2) < RESOLUTION) clockSelectBits = _BV(CS12); // prescale by /256
else if((cycles >>= 2) < RESOLUTION) clockSelectBits = _BV(CS12) | _BV(CS10); // prescale by /1024
else cycles = RESOLUTION - 1, clockSelectBits = _BV(CS12) | _BV(CS10); // request was out of bounds, set as maximum
oldSREG = SREG;
cli(); // Disable interrupts for 16 bit register access
ICR1 = pwmPeriod = cycles; // ICR1 is TOP in p & f correct pwm mode
SREG = oldSREG;
TCCR1B &= ~(_BV(CS10) | _BV(CS11) | _BV(CS12));
TCCR1B |= clockSelectBits; // reset clock select register, and starts the clock
}
the first line has both a multiply and worse, a signed 32 bit divide. that blows my mind. removing that divide will give me a ton of headroom. it has to be eating up at _least_ 25 us every step. i guess i never wondered why this library let me specify periods in exact microseconds
ok...time to fix this and see some super speeds EDIT: i'm retarded. it's a division between two constants. the 32 bit signed multiply is no good, so there is still an optimization available, just not at the scale as it would have been with divide.
Edited 2 time(s). Last edit at 11/10/2011 11:22PM by hardtoe.
|
Re: new firmware: Jagon by Hardtoe November 10, 2011 11:38PM |
Registered: 12 years ago Posts: 74 |
so i removed that multiplication and just keep the prescale at 8. then it will work fine on 16MHz Arduinos. will end up needing some mechanism to correct for this on other micros...but that could be done outside of the step loop.
anyways, i'm at 48 us. still not fast enough. but i have more items to look at.
anyways, i'm at 48 us. still not fast enough. but i have more items to look at.
|
Re: new firmware: Jagon by Hardtoe November 11, 2011 02:56AM |
Registered: 12 years ago Posts: 2,705 |
24 Bit integers - don't do it. You get yourself only into troubles. I looked for that, too. After doing some math on the extreme values, I often ended with 32 bit for some special cases. Think of F_CPU. Most have 16MHz which fits, but GEN7 has 20 MHz and xMegas can have up to 32 MHz if someone starts using them. Sometimes I even switched to float to prevent overflows!
It's easier to stay with 32 bit and if you see a long and frequent used computation, try optimizing exactly that formula.
hardtoe Wrote:
-------------------------------------------------------
> so i removed that multiplication and just keep the
> prescale at 8. then it will work fine on 16MHz
> Arduinos. will end up needing some mechanism to
> correct for this on other micros...but that could
> be done outside of the step loop.
>
Marlin uses only a prescale of 8, which is good enough. I used exact timings with no prescale, but I check the overflows at the beginning of the isr and skip if overflow>0. So I get exact timings for any time up to 4000000000 ticks. Enough for range super speed to incredibly slow.
Repetier-Software - the home of Repetier-Host (Windows, Linux and Mac OS X) and Repetier-Firmware.
Repetier-Server - the solution to control your printer from everywhere.
Visit us on Facebook and Twitter!
It's easier to stay with 32 bit and if you see a long and frequent used computation, try optimizing exactly that formula.
hardtoe Wrote:
-------------------------------------------------------
> so i removed that multiplication and just keep the
> prescale at 8. then it will work fine on 16MHz
> Arduinos. will end up needing some mechanism to
> correct for this on other micros...but that could
> be done outside of the step loop.
>
Marlin uses only a prescale of 8, which is good enough. I used exact timings with no prescale, but I check the overflows at the beginning of the isr and skip if overflow>0. So I get exact timings for any time up to 4000000000 ticks. Enough for range super speed to incredibly slow.
Repetier-Software - the home of Repetier-Host (Windows, Linux and Mac OS X) and Repetier-Firmware.
Repetier-Server - the solution to control your printer from everywhere.
Visit us on Facebook and Twitter!
|
Re: new firmware: Jagon by Hardtoe November 11, 2011 03:36AM |
Registered: 12 years ago Posts: 74 |
Thanks again for the tips repetier. I had actually started creating the uint24_t data type along with addition and subtraction operators written in assembly. It worked just fine in my little testbench, but I noticed that avr-gcc did not optimize any of the assembler. So every instruction I specified was stuffed into the final output. If I wasn't careful with how I use the uint24 integers, I could create less efficient code in addition to increasing the opportunity for overflows.
So that didn't pan out as expected. However, I now know how to code inline assembly, so maybe I'll write part of the StepperDriver in assembly to see how that goes.
I also need a way to identify the hotspots in my code. How did you know where your bottlenecks were?
So that didn't pan out as expected. However, I now know how to code inline assembly, so maybe I'll write part of the StepperDriver in assembly to see how that goes.
I also need a way to identify the hotspots in my code. How did you know where your bottlenecks were?
|
Re: new firmware: Jagon by Hardtoe November 11, 2011 03:38AM |
Registered: 13 years ago Posts: 7,616 |
(F_CPU / 2000000)This is not really a divide, as both are constant, so optimisation will replace that with the also constant result.
| Generation 7 Electronics | Teacup Firmware | RepRap DIY |
|
Re: new firmware: Jagon by Hardtoe November 11, 2011 03:43AM |
Registered: 14 years ago Posts: 3,742 |
It has nothing to do with optimization, it has to do with compilation, in short anything that can be resolved/calculated at compile time is generally done at compile time. Optimization is a totally different animal (that also takes place during compilation creating different assembly code optimized either for code size, execution speed, or possibly even ram usage).
Bob Morrison
Wörth am Rhein, Germany
"Luke, use the source!"
BLOG - PHOTOS - Thingiverse
Bob Morrison
Wörth am Rhein, Germany
"Luke, use the source!"
BLOG - PHOTOS - Thingiverse
|
Re: new firmware: Jagon by Hardtoe November 11, 2011 04:52AM |
Registered: 16 years ago Posts: 1,094 |
fyi, teacup has a 4-D bresenham implementation that can easily be extended to any number of dimensions, and does not store any concept of a master axis. It's hard-coded for 4 but could easily be stuck in a 'for' loop or a C++ class.
buffering step times is an interesting optimisation, you could fill it easily during coast. As we tend to use pretty high accel if we can get away with it, even a small-ish buffer could work well.
How do you handle the junction between moves? With a trajectory planner, you can have one axis slow down and reverse while another keeps barreling along at full speed, don't want to have to queue-flush then hope to pick up the other side quick enough..
please use macros or calculations in your divide optimiser and timer stuff, it's more common than you may think to have alternate crystals in our arduinos. one of mine has a 16MHz, the other has a 20MHz.
I'm using 3000mm/s/s accel at the moment, if you're curious for numbers to play with.
-----------------------------------------------
Wooden Mendel
Teacup Firmware
buffering step times is an interesting optimisation, you could fill it easily during coast. As we tend to use pretty high accel if we can get away with it, even a small-ish buffer could work well.
How do you handle the junction between moves? With a trajectory planner, you can have one axis slow down and reverse while another keeps barreling along at full speed, don't want to have to queue-flush then hope to pick up the other side quick enough..
please use macros or calculations in your divide optimiser and timer stuff, it's more common than you may think to have alternate crystals in our arduinos. one of mine has a 16MHz, the other has a 20MHz.
I'm using 3000mm/s/s accel at the moment, if you're curious for numbers to play with.
-----------------------------------------------
Wooden Mendel
Teacup Firmware
|
Re: new firmware: Jagon by Hardtoe November 11, 2011 06:38PM |
Registered: 12 years ago Posts: 74 |
thanks again for the insight everyone!
i've spent some more time optimizing the timer, the division algorithm, StepperDriver and the StepPlanner. i was able to get the min step period down to 36us from 48us. in order to support 32.5KHz, i'll need to get my calculations down to 30us.
the only time the stepCommandQueue ever needs to be flushed is during a homing operation. that's because we want feedback on whether the endstops have been hit or not. for every other case, the communication only flows in one direction. so it'll never need to flush any queues while at speed during a print.
once the remaining steps of a move have been queued up, the next move command is fetched from the MoveCommandQueue. Once the initial values are calculated for the move, the StepPlanner starts queuing up the corresponding steps. As long as the StepCommandQueue doesn't underflow, there will be no pause at all between moves.
I started adding macros to the fast division algorithm, it will handle different cpu frequencies as well as different min delay periods.
latest code up to this update has been pushed to the Jagon github.
Quote
repetier
Acceleration to 18000 is not fast enough. Some peaple have extruder with 1300 Steps/mm and want it to run at 25 mm/s for fast retracts. That's 32500 Hz. I never thought of this, until they complained some errors due to this high frequency. Off couse, you can always clamp this to possible speeds. Still better then missing steps or nothing.
i've spent some more time optimizing the timer, the division algorithm, StepperDriver and the StepPlanner. i was able to get the min step period down to 36us from 48us. in order to support 32.5KHz, i'll need to get my calculations down to 30us.
Quote
Triffid_Hunter
How do you handle the junction between moves? With a trajectory planner, you can have one axis slow down and reverse while another keeps barreling along at full speed, don't want to have to queue-flush then hope to pick up the other side quick enough..
please use macros or calculations in your divide optimiser and timer stuff, it's more common than you may think to have alternate crystals in our arduinos. one of mine has a 16MHz, the other has a 20MHz.
the only time the stepCommandQueue ever needs to be flushed is during a homing operation. that's because we want feedback on whether the endstops have been hit or not. for every other case, the communication only flows in one direction. so it'll never need to flush any queues while at speed during a print.
once the remaining steps of a move have been queued up, the next move command is fetched from the MoveCommandQueue. Once the initial values are calculated for the move, the StepPlanner starts queuing up the corresponding steps. As long as the StepCommandQueue doesn't underflow, there will be no pause at all between moves.
I started adding macros to the fast division algorithm, it will handle different cpu frequencies as well as different min delay periods.
latest code up to this update has been pushed to the Jagon github.
|
Re: new firmware: Jagon by Hardtoe November 11, 2011 09:14PM |
Registered: 12 years ago Posts: 74 |
i managed to print out a little squirrel with Jagon. it turned out OK, however there are a few defects:
1) my printer skipped some steps on a couple of the layers. i'm thinking that's because i used to print with 1000mm/s/s acceleration, and now i tried this print at 1500.
2) the filament wasn't retracting fast enough, i believe that's because i'm not allowing any stepper motor to move faster than a 40us period would allow. i need to change my acceleration calculations so that each axis has independent acceleration limits.
3) at the end of the print, the printer stopped pushing filament forward, instead it seemed to go backwards. that may be due to an overflow somewhere as i'm using absolute coordinates for my E axis.
1) my printer skipped some steps on a couple of the layers. i'm thinking that's because i used to print with 1000mm/s/s acceleration, and now i tried this print at 1500.
2) the filament wasn't retracting fast enough, i believe that's because i'm not allowing any stepper motor to move faster than a 40us period would allow. i need to change my acceleration calculations so that each axis has independent acceleration limits.
3) at the end of the print, the printer stopped pushing filament forward, instead it seemed to go backwards. that may be due to an overflow somewhere as i'm using absolute coordinates for my E axis.

|
Re: new firmware: Jagon by Hardtoe November 12, 2011 05:42AM |
Registered: 13 years ago Posts: 7,616 |
Quote
i was able to get the min step period down to 36us from 48us.
A side question: how do you get such numbers? By counting instructions? By moving the axis faster until you get an interrupt flood?
| Generation 7 Electronics | Teacup Firmware | RepRap DIY |
|
Re: new firmware: Jagon by Hardtoe November 12, 2011 06:04AM |
Registered: 12 years ago Posts: 74 |
Quote
Traumflug
A side question: how do you get such numbers? By counting instructions? By moving the axis faster until you get an interrupt flood?
i have a print statement in the StepperDriver interrupt routine. it keeps track of StepCommandQueue underflows. every time it underflows, it prints out a number that increments once for each underflow.
From StepperDriver:
inline void interrupt() {
StepCommand* currentCommand;
if (stepCommandBuffer->notEmpty()) {
// cutting out all of the actual stepping code to keep the forum post shorter
skippedLast = false;
} else {
if (!skippedLast) {
Serial.println((unsigned int) skips++);
}
skippedLast = true;
}
}
so i've just been decreasing the min step time in my StepPlanner code until i see all these underflow errors. at that point I know i've gone too far and i need to back off the min step time or find some code to optimize.
From StepPlanner:
#define MIN_STEP_DELAY 35
EDIT: s/overflow/underflow/
Edited 1 time(s). Last edit at 11/12/2011 06:04AM by hardtoe.
|
Re: new firmware: Jagon by Hardtoe November 12, 2011 06:26AM |
Registered: 12 years ago Posts: 74 |
so right now i have a very simple algorithm for calculating my velocity ramp:
i ran a simple benchmark and this code seems to be taking up a fair amount of execution time. i think there's enough to shave a few more microseconds of my step processing time.
my plan is to move part of this logic into the MovePlanner. the MovePlanner will then split each segment move into three parts, acceleration, constant velocity and deceleration MoveCommands. this way the StepPlanner doesn't need to calculate the ramp on the fly. instead, it will apply whatever the acceleration value is from the MoveCommand. additionally, the StepPlanner will be able to bypass this code entirely for constant velocity moves.
in the processing of moving the acceleration stuff into the MovePlanner, I'm also going to fix the code to choose proper velocities and acceleration values. right now it's just using the velocity of the longest travel axis and a fixed acceleration for all axis. that's wrong and caused problems with my test print. shouldn't be too hard to fix that, i've got something in mind already.
that should bring me really close to 32.5KHz. if that doesn't do it, there's still another opportunity to save some time in the StepperDriver interrupt routine. otherwise i'll need to start optimizing some code into assembly or finding some clever tricks.
inline void calculateVelocity() {
if (accelerationConstant != 0) {
// check if we need to update velocity
currentVelocityError +=
currentStepDelay;
if (currentVelocityError > accelerationConstant) {
do {
currentVelocityError -= accelerationConstant;
if (numStepsLeft < (numSteps >> 1)) {
currentVelocity += VELOCITY_RESOLUTION;
} else {
currentVelocity -= VELOCITY_RESOLUTION;
}
} while (currentVelocityError > accelerationConstant);
currentStepDelay = fastDivide(currentVelocity);
if (currentVelocity <= maxVelocity) {
prototypeStep.setStepDelay(currentStepDelay);
}
}
}
}
i ran a simple benchmark and this code seems to be taking up a fair amount of execution time. i think there's enough to shave a few more microseconds of my step processing time.
my plan is to move part of this logic into the MovePlanner. the MovePlanner will then split each segment move into three parts, acceleration, constant velocity and deceleration MoveCommands. this way the StepPlanner doesn't need to calculate the ramp on the fly. instead, it will apply whatever the acceleration value is from the MoveCommand. additionally, the StepPlanner will be able to bypass this code entirely for constant velocity moves.
in the processing of moving the acceleration stuff into the MovePlanner, I'm also going to fix the code to choose proper velocities and acceleration values. right now it's just using the velocity of the longest travel axis and a fixed acceleration for all axis. that's wrong and caused problems with my test print. shouldn't be too hard to fix that, i've got something in mind already.
that should bring me really close to 32.5KHz. if that doesn't do it, there's still another opportunity to save some time in the StepperDriver interrupt routine. otherwise i'll need to start optimizing some code into assembly or finding some clever tricks.
|
Re: new firmware: Jagon by Hardtoe November 12, 2011 08:06AM |
Registered: 16 years ago Posts: 1,094 |
Getting rid of the reliance on speedy ramp generation for eradicating inter-move delays is interesting with this architecture- you need to somehow insert a marker to pull the next set of directions and step masks into the step time queue- perhaps a zero value, or a -1? Then you can queue up multiple blended moves if possible/necessary complete with direction changes.
hardtoe Wrote:
-------------------------------------------------------
> so right now i have a very simple algorithm for
> calculating my velocity ramp:
Does that create a linear increase and decrease in velocity? There are a surprising number of simple algorithms that sound good at first, until you realise that they cause exponential increase in velocity, eg; the original FiveD firmware algorithm.
> my plan is to move part of this logic into the
> MovePlanner. the MovePlanner will then split each
> segment move into three parts, acceleration,
> constant velocity and deceleration MoveCommands.
> this way the StepPlanner doesn't need to calculate
> the ramp on the fly. instead, it will apply
> whatever the acceleration value is from the
> MoveCommand. additionally, the StepPlanner will
> be able to bypass this code entirely for constant
> velocity moves.
[www.eetimes.com] is a fantastic article for doing good ramps quickly and efficiently.
It requires doing some pre-move setup with floats, then boils down to a few integers which you can use to generate the entire ramp using only a few adds and multiplies, and one divide per step.
> in the processing of moving the acceleration stuff
> into the MovePlanner, I'm also going to fix the
> code to choose proper velocities and acceleration
> values. right now it's just using the velocity of
> the longest travel axis and a fixed acceleration
> for all axis. that's wrong and caused problems
> with my test print. shouldn't be too hard to fix
> that, i've got something in mind already.
I had a big chat with ScribbleJ about this when he was implementing the same thing for sjfw.
Basically the idea is to work out feedrate. and accel and decel distances or times along the movement vector, then break them down into XYZE components afterwards and apply to each axis. Then, check and apply limits. If anything was limited, you'll have to map back onto the vector and break into components again, or do a ratiometric adjustment of every other axis.
Once that's complete, you can use the values from your bresenham master and start firing off pulses safe in the knowledge that all axis limits are being obeyed, and that the feedrate is along the motion vector so your circles will print at a constant speed
You may also want to consider a combined XY acceleration in the 2d cartesian plane, so that acceleration for moves in various orientations is consistent too.
on a totally unrelated note, in your heatercontroller.h, it looks like M109 Snnn won't set the heater to nnn first then wait for it to catch up. Please support both M109 by itself, and M109 Snnn
-----------------------------------------------
Wooden Mendel
Teacup Firmware
hardtoe Wrote:
-------------------------------------------------------
> so right now i have a very simple algorithm for
> calculating my velocity ramp:
Does that create a linear increase and decrease in velocity? There are a surprising number of simple algorithms that sound good at first, until you realise that they cause exponential increase in velocity, eg; the original FiveD firmware algorithm.
> my plan is to move part of this logic into the
> MovePlanner. the MovePlanner will then split each
> segment move into three parts, acceleration,
> constant velocity and deceleration MoveCommands.
> this way the StepPlanner doesn't need to calculate
> the ramp on the fly. instead, it will apply
> whatever the acceleration value is from the
> MoveCommand. additionally, the StepPlanner will
> be able to bypass this code entirely for constant
> velocity moves.
[www.eetimes.com] is a fantastic article for doing good ramps quickly and efficiently.
It requires doing some pre-move setup with floats, then boils down to a few integers which you can use to generate the entire ramp using only a few adds and multiplies, and one divide per step.
> in the processing of moving the acceleration stuff
> into the MovePlanner, I'm also going to fix the
> code to choose proper velocities and acceleration
> values. right now it's just using the velocity of
> the longest travel axis and a fixed acceleration
> for all axis. that's wrong and caused problems
> with my test print. shouldn't be too hard to fix
> that, i've got something in mind already.
I had a big chat with ScribbleJ about this when he was implementing the same thing for sjfw.
Basically the idea is to work out feedrate. and accel and decel distances or times along the movement vector, then break them down into XYZE components afterwards and apply to each axis. Then, check and apply limits. If anything was limited, you'll have to map back onto the vector and break into components again, or do a ratiometric adjustment of every other axis.
Once that's complete, you can use the values from your bresenham master and start firing off pulses safe in the knowledge that all axis limits are being obeyed, and that the feedrate is along the motion vector so your circles will print at a constant speed
You may also want to consider a combined XY acceleration in the 2d cartesian plane, so that acceleration for moves in various orientations is consistent too.
on a totally unrelated note, in your heatercontroller.h, it looks like M109 Snnn won't set the heater to nnn first then wait for it to catch up. Please support both M109 by itself, and M109 Snnn
-----------------------------------------------
Wooden Mendel
Teacup Firmware
|
Re: new firmware: Jagon by Hardtoe November 12, 2011 01:34PM |
Registered: 12 years ago Posts: 74 |
Quote
Triffid_Hunter
Getting rid of the reliance on speedy ramp generation for eradicating inter-move delays is interesting with this architecture- you need to somehow insert a marker to pull the next set of directions and step masks into the step time queue- perhaps a zero value, or a -1? Then you can queue up multiple blended moves if possible/necessary complete with direction changes.
i'm not sure what you mean by marker. the firmware has a CircularBuffer class that handles the queues between stages. when a pipeline stage is ready to process a command from its input queue, it uses the protothread library to wait until that queue is not empty. other threads will execute while it's waiting for that queue.
once the queue has an item to process, the pipeline stage will retrieve the command from the queue and process it. then it will use the protothread library to wait for space in the destination queue to put the results.
the CircularBuffer class is managed internally using size, enqueuePointer and dequeuePointer values.
i think that's basically what you were asking about, but i'm not 100% sure.
Quote
Triffid_Hunter
Does that create a linear increase and decrease in velocity? There are a surprising number of simple algorithms that sound good at first, until you realise that they cause exponential increase in velocity, eg; the original FiveD firmware algorithm.
i'm pretty sure the velocity ramp algorithm is linear. i designed it so it would execute quickly for short step periods, but may take longer for longer step periods.
i updated the code to describe how it works a little better:
/**
* calculate velocity for next step. this can be thought of as a 2D Bresenham
* algorithm where one dimension is the velocity in steps per second, and the
* other dimension is time in microseconds.
*
* runtime is slower for long periods due to looping through the velocity
* calculation multiple times.
*
* runtime for short periods is very fast *per period* because we may only
* loop once or even not at all.
*
* runtime for constant velocity moves should be very good as the entire
* algorithm will be skipped.
*/
inline void calculateVelocity() {
if (accelerationConstant != 0) {
// accumulate how long its been since the last velocity increase
currentVelocityError +=
currentStepDelay;
// if it's been longer than the period we need to increase velocity linearly...
if (currentVelocityError > accelerationConstant) {
do {
// ...then remove the length of the period to increase velocity...
currentVelocityError -= accelerationConstant;
// ...figure out whether we should increase or decrease our velocity using
// a cheapo ramp function...
if (numStepsLeft < (numSteps >> 1)) {
currentVelocity += VELOCITY_RESOLUTION;
} else {
currentVelocity -= VELOCITY_RESOLUTION;
}
// ...and keep looping until we have accumulated the correct velocity
} while (currentVelocityError > accelerationConstant);
// convert the calculated velocity into a step delay using a fast division algorithm
currentStepDelay = fastDivide(currentVelocity);
// clamp the max velocity
if (currentVelocity <= maxVelocity) {
prototypeStep.setStepDelay(currentStepDelay);
}
}
}
}
i also took a look at the eetimes article you linked to. that's a pretty slick algorithm, but it requires multiply as well as a divide. the divide i have is easy to optimize because the dividend is constant. so for the smallest periods, i can just use an if/else tree and it's faster than any other division algorithm for 8-bit atmegas.
Quote
Triffid_Hunter
on a totally unrelated note, in your heatercontroller.h, it looks like M109 Snnn won't set the heater to nnn first then wait for it to catch up. Please support both M109 by itself, and M109 Snnn
i took a quick look at the waitExtruderTemp function that gets called for M109. i believe it is correct, i think that my method names might not be very clear in this case. i added some comments that should help out.
inline int waitExtruderTemp(float targetTemp) {
PT_YIELDING();
PT_BEGIN(&subState);
// if targetTemp is a real number...
if (!isnan(targetTemp)) {
// ...tell heaterZero (extruder) to warm up to targetTemp
heaterZero->setTarget(targetTemp);
}
// while heaterZero (extruder) has not yet reached the target temp...
while (!heaterZero->atTargetTemp()) {
// ...delay for 1 second (allowing other threads to execute in the meantime)...
PT_DELAY(&subState, 1000);
// ...and report the current temperatures back to the host
readCurrentTemp();
}
PT_END(&subState);
}
|
Re: new firmware: Jagon by Hardtoe November 12, 2011 06:52PM |
Registered: 16 years ago Posts: 1,094 |
hardtoe Wrote:
-------------------------------------------------------
> once the queue has an item to process, the
> pipeline stage will retrieve the command from the
> queue and process it. then it will use the
> protothread library to wait for space in the
> destination queue to put the results.
>
> the CircularBuffer class is managed internally
> using size, enqueuePointer and dequeuePointer
> values.
yeah I get that it's a typical ringbuffer, perhaps I'm not explaining myself clearly.
We're drawing a curve that joins a straight line. This has a junction where one axis stops, and the other can keep moving at speed.
At the junction, where (let's say) X stops but Y keeps going, you must change your step mask while keeping up with Y. Since this is a change in direction, Y will probably be ramping down and back up, so the changeover occurs while Y is ramping. If the feedrate is only slightly above the jerk velocity, then Y will only ramp a little bit, and still be moving quite quickly through the junction.
If I understand your architecture correctly, the step timer buffer is emptied at the end of the first move, so you can switch the step mask then start re-filling the buffer with Y's ramp-up. I'm suggesting that it would be best to buffer the step and direction masks too, and use some sort of marker in the step timer buffer to mark when to pull the new mask.
> i'm pretty sure the velocity ramp algorithm is
> linear. i designed it so it would execute quickly
> for short step periods, but may take longer for
> longer step periods.
>
> i also took a look at the eetimes article you
> linked to. that's a pretty slick algorithm, but
> it requires multiply as well as a divide. the
> divide i have is easy to optimize because the
> dividend is constant. so for the smallest
> periods, i can just use an if/else tree and it's
> faster than any other division algorithm for 8-bit
> atmegas.
awesome, just making sure we don't have to go through "exponential changes in velocity are bad, even though the code is simpler" again
> i took a quick look at the waitExtruderTemp
> function that gets called for M109. i believe it
> is correct, i think that my method names might not
> be very clear in this case. i added some comments
> that should help out.
>
> inline int waitExtruderTemp(float targetTemp)
ah ok I see now, but at line 61, what happens if there's no S parameter, ie just a bare M109?
My start.gcode has a bare M109, so it sits and waits for whatever temperature user has set previously, and I can reuse the same gcode with different temperatures and it'll behave correctly (in sprinter at least, and teacup too I think).
There' s no guarantee that you can use a leftover S, what happens if someone sends M104 S210, M140 S60, M109 ?
-----------------------------------------------
Wooden Mendel
Teacup Firmware
-------------------------------------------------------
> once the queue has an item to process, the
> pipeline stage will retrieve the command from the
> queue and process it. then it will use the
> protothread library to wait for space in the
> destination queue to put the results.
>
> the CircularBuffer class is managed internally
> using size, enqueuePointer and dequeuePointer
> values.
yeah I get that it's a typical ringbuffer, perhaps I'm not explaining myself clearly.
We're drawing a curve that joins a straight line. This has a junction where one axis stops, and the other can keep moving at speed.
At the junction, where (let's say) X stops but Y keeps going, you must change your step mask while keeping up with Y. Since this is a change in direction, Y will probably be ramping down and back up, so the changeover occurs while Y is ramping. If the feedrate is only slightly above the jerk velocity, then Y will only ramp a little bit, and still be moving quite quickly through the junction.
If I understand your architecture correctly, the step timer buffer is emptied at the end of the first move, so you can switch the step mask then start re-filling the buffer with Y's ramp-up. I'm suggesting that it would be best to buffer the step and direction masks too, and use some sort of marker in the step timer buffer to mark when to pull the new mask.
> i'm pretty sure the velocity ramp algorithm is
> linear. i designed it so it would execute quickly
> for short step periods, but may take longer for
> longer step periods.
>
> i also took a look at the eetimes article you
> linked to. that's a pretty slick algorithm, but
> it requires multiply as well as a divide. the
> divide i have is easy to optimize because the
> dividend is constant. so for the smallest
> periods, i can just use an if/else tree and it's
> faster than any other division algorithm for 8-bit
> atmegas.
awesome, just making sure we don't have to go through "exponential changes in velocity are bad, even though the code is simpler" again
> i took a quick look at the waitExtruderTemp
> function that gets called for M109. i believe it
> is correct, i think that my method names might not
> be very clear in this case. i added some comments
> that should help out.
>
> inline int waitExtruderTemp(float targetTemp)
ah ok I see now, but at line 61, what happens if there's no S parameter, ie just a bare M109?
My start.gcode has a bare M109, so it sits and waits for whatever temperature user has set previously, and I can reuse the same gcode with different temperatures and it'll behave correctly (in sprinter at least, and teacup too I think).
There' s no guarantee that you can use a leftover S, what happens if someone sends M104 S210, M140 S60, M109 ?
-----------------------------------------------
Wooden Mendel
Teacup Firmware
|
Re: new firmware: Jagon by Hardtoe November 12, 2011 07:33PM |
Registered: 12 years ago Posts: 74 |
Quote
Triffid_Hunter
If I understand your architecture correctly, the step timer buffer is emptied at the end of the first move, so you can switch the step mask then start re-filling the buffer with Y's ramp-up. I'm suggesting that it would be best to buffer the step and direction masks too, and use some sort of marker in the step timer buffer to mark when to pull the new mask.
i see what your saying now. that's actually how it works. the StepperDriver executes StepCommands and each StepCommand has all the information necessary for that step: what stepper motors to step, what stepper motors to enable/disable, step direction and how long to wait before executing the next StepCommand.
so it will buffer up StepCommands across multiple moves without waiting for the stepCommandQueue to empty.
Quote
Triffid_Hunter
ah ok I see now, but at line 61, what happens if there's no S parameter, ie just a bare M109?
My start.gcode has a bare M109, so it sits and waits for whatever temperature user has set previously, and I can reuse the same gcode with different temperatures and it'll behave correctly (in sprinter at least, and teacup too I think).
There' s no guarantee that you can use a leftover S, what happens if someone sends M104 S210, M140 S60, M109 ?
the GCode class represents only one gcode, it will not persist any values between gcode commands. so if a particular parameter was not present, the value of that parameter will be a floating point NaN.
each Heater class keeps track of what their set temperature is. when you set the temperature of a Heater, it clears a flag that says it has reached it's target. when the Heater turns the heating element off, it knows that it can set that flag.
so the Heater atTargetTemp() method just returns that flag.
added more in the edit:
so here's what happens:
M104 S210 // extruder target temp is set to 210, extruder.atTarget flag is cleared
M140 S60 // extruder target temp is set to 60, extruder.atTarget flag is cleared, HeaterController waits until extruder atTarget flag is set
M109 // HeaterController waits until heated bed atTarget flag is set (if you haven't set a temp before, this will complete immediately)
Edited 1 time(s). Last edit at 11/12/2011 07:37PM by hardtoe.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Sorry, only registered users may post in this forum.